Vysvětlení AI pomáhá jen tehdy, když odporuje vaší intuici
Dva experimenty s doménovými experty ukazují, že XAI vysvětlení zlepšuje metakognitivní přesnost a kvalitu delegování na AI. Ale pouze v jednom případě: když AI uvažuje jinak než člověk.
Foto: FAIN News
Tento článek vznikl agregací informací z veřejně dostupných zdrojů. Nejsme primární zdroj — původní zdroje najdete níže. Mohou vzniknout nepřesnosti.
Tento článek vznikl agregací informací z veřejně dostupných zdrojů. Nejsme primární zdroj — původní zdroje najdete níže. Mohou vzniknout nepřesnosti.
Dva experimenty s doménovými experty ukazují, že XAI vysvětlení zlepšuje metakognitivní přesnost a kvalitu delegování na AI. Ale pouze v jednom případě: když AI uvažuje jinak než člověk. Pokud vysvětlení potvrzuje to, co si expert už myslel, nepomáhá.
✅ Peer-reviewed · Publikováno 2025 · Data sbírána [období neupřesněno v dostupných zdrojích] · Information Systems Research
Co studie zjistila
Výzkumný tým z Goethe University Frankfurt provedl dva incentivizované experimenty, ve kterých doménoví experti opakovaně řešili predikční úlohy s možností delegovat každý úkol na AI. Klíčová manipulace: některým účastníkům bylo předem ukázáno vysvětlení celkové predikční logiky AI systému, jiným ne.
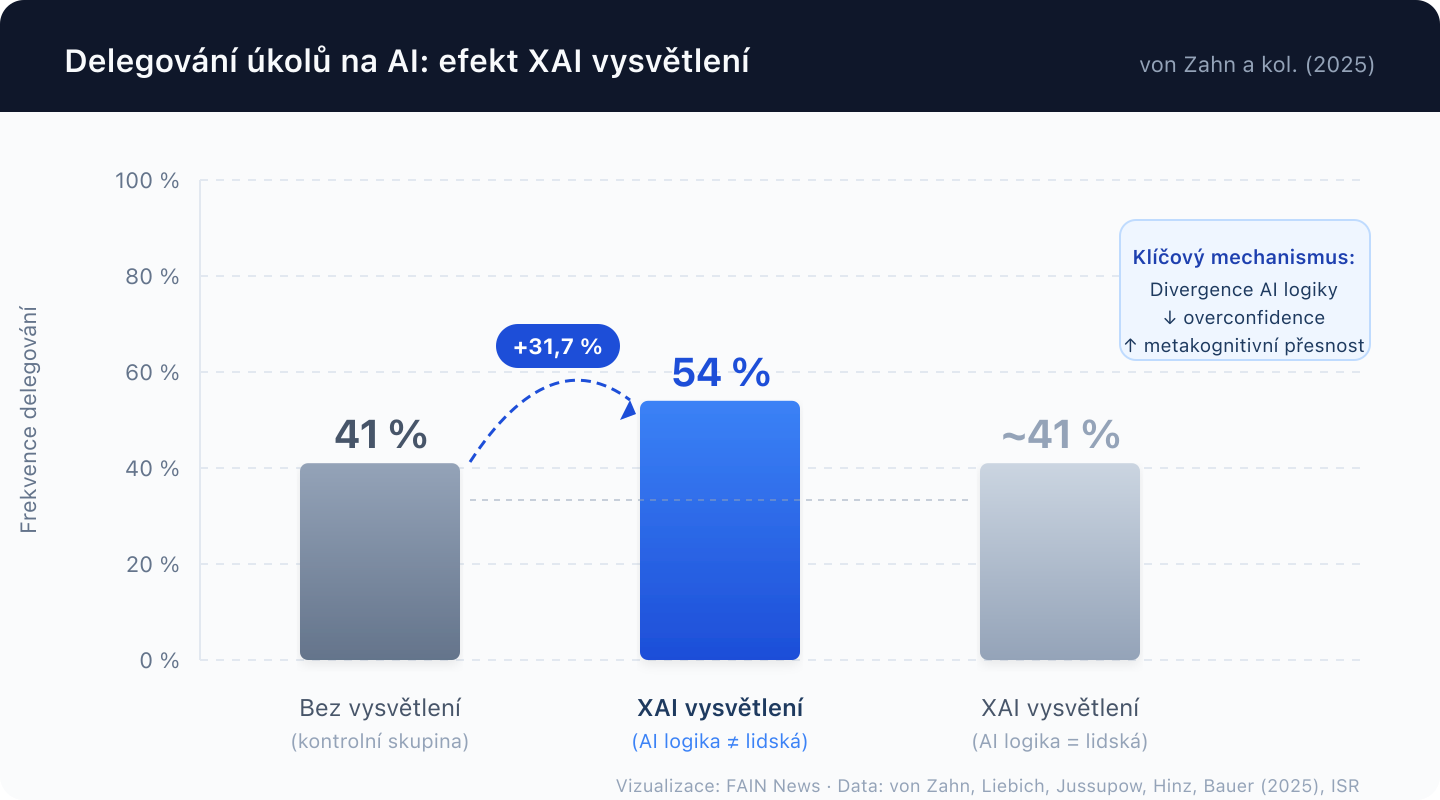
Hlavní zjištění je překvapivě podmíněné. XAI vysvětlení zvyšuje tzv. metakognitivní přesnost, tedy to, jak dobře člověk odhaduje svou vlastní schopnost úkol zvládnout. To následně zvyšuje jak frekvenci, tak efektivitu delegování na AI. V jednom z experimentů vzrostla frekvence delegování ze 41 % na 54 % (nárůst o 31,7 %, p < 0,01).
📚 Metakognitivní přesnost (Flavell, 1979)
Metakognice je „myšlení o myšlení". Metakognitivní přesnost měří, jak dobře se shoduje vaše subjektivní přesvědčení o vlastních schopnostech s vaším reálným výkonem. Pokud jste si jistí, že úkol zvládnete, a skutečně ho zvládnete, vaše metakognitivní přesnost je vysoká. Pokud jste si jistí, ale selžete (nadměrná sebedůvěra), je nízká. V kontextu spolupráce s AI je metakognitivní přesnost klíčová: člověk, který přesně ví, co zvládne a co ne, dokáže lépe rozhodovat, kdy úkol delegovat na AI.
Ale tady přichází twist. Efekt nastává pouze tehdy, když vysvětlení odhalí, že AI uvažuje jinak než člověk. Když AI dojde ke stejnému závěru stejnou logikou, vysvětlení nepomáhá. Jen potvrzuje to, co si expert už myslel, a metakognice se nezlepší.
Jinými slovy: vysvětlení AI má hodnotu nikoliv proto, že ukazuje, jak AI funguje, ale proto, že odhaluje slepá místa v lidském uvažování. Divergence mezi vlastním a AI přístupem funguje jako kognitivní zrcadlo.
 Vizualizace: FAIN News na základě dat z von Zahn, Liebich, Jussupow, Hinz, Bauer (2025), Information Systems Research.
Vizualizace: FAIN News na základě dat z von Zahn, Liebich, Jussupow, Hinz, Bauer (2025), Information Systems Research.
📚 Overconfidence bias (Kahneman & Tversky)
Systematická tendence nadhodnocovat vlastní znalosti, schopnosti nebo přesnost vlastních úsudků. V odborných profesích je overconfidence paradoxně častější, protože experti mají tendenci spoléhat na intuici vybudovanou praxí, i v situacích, kde intuice selhává. Studie von Zahna a kol. ukazuje, že XAI může overconfidence snížit tím, že expertovi ukáže alternativní logiku. Má to ale vedlejší efekt: u některých účastníků XAI snížilo sebedůvěru i v případech, kdy ji měli oprávněnou.
Jak to zjistili
Autoři provedli dva experimenty s reálnými doménovými experty, nikoli se studenty. V obou případech šlo o incentivizované experimenty, kde účastníci opakovaně řešili predikční úlohy s možností delegovat jednotlivé úkoly na AI systém. Experimentální manipulace spočívala v tom, zda účastníci na začátku dostali vysvětlení celkové predikční logiky AI.
Druhý experiment zahrnoval 200 účastníků z finančního a pojišťovacího sektoru, rekrutovaných přes platformu Prolific. Jejich úkolem bylo predikovat, zda dlužník splatí P2P půjčku, přičemž pracovali s historickými daty z platformy LendingClub.
🔍 Incentivizovaný experiment
Experimentální design, ve kterém jsou účastníci finančně motivováni k co nejlepšímu výkonu. Na rozdíl od běžných dotazníkových studií, kde odpovědi nemají reálné důsledky, incentivizované experimenty minimalizují „klikání naslepo" a přibližují chování v laboratoři reálnému rozhodování. V kontextu AI delegování je to zásadní: účastník musí skutečně zvážit, jestli úkol zvládne lépe sám, nebo ho má svěřit AI.
Klíčová měřená proměnná byla metakognitivní přesnost, tedy korelace mezi subjektivní jistotou účastníka a jeho skutečným výkonem. Autoři sledovali, jak se tato přesnost mění v závislosti na přítomnosti XAI vysvětlení a na míře divergence mezi logikou AI a logikou účastníka.
Proč je to důležité
Studie přináší tři zásadní vhledy. Za prvé, mění optiku diskuze o XAI. Dosavadní výzkum se soustředil na otázku, zda vysvětlení zvyšuje důvěru v AI nebo zlepšuje přesnost rozhodování. Von Zahn a kol. ukazují třetí, dosud přehlíženou cestu: XAI ovlivňuje, jak dobře lidé rozumí sami sobě. To je fundamentálně jiný mechanismus než „trust calibration".
Za druhé, má přímé implikace pro implementaci AI v organizacích. Pokud vysvětlení pomáhá jen tehdy, když odhaluje rozdíl, pak systémy, které prezentují AI logiku shodnou s lidskou intuicí, plýtvají kognitivním úsilím uživatele bez přidané hodnoty. Adaptivní XAI, které zvýrazní momenty divergence, by bylo efektivnější.
Za třetí, studie je vysoce relevantní pro regulatorní kontext. EU AI Act v článku 13 požaduje transparentnost a vysvětlitelnost u vysoce rizikových AI systémů. Zjištění naznačuje, že pouhá přítomnost vysvětlení nestačí. Záleží na tom, jak vysvětlení interaguje s existujícím mentálním modelem uživatele. Pro firmy implementující compliance s AI Act to znamená: nestačí „přidat vysvětlení", je třeba designovat vysvětlení tak, aby byla kognitivně užitečná.
Limity a otevřené otázky
Studie má několik omezení. Experiment 2 pracuje se vzorkem 200 účastníků rekrutovaných přes Prolific, což je solidní velikost pro experimentální design, ale omezuje generalizovatelnost na konkrétní populaci finančních profesionálů v online prostředí. Jak by se efekt projevil u jiných domén (medicína, právo, HR) nebo v reálném pracovním prostředí s vyšším tlakem a komplexnějšími rozhodnutími, zůstává otevřenou otázkou.
Autoři sami upozorňují na vedlejší efekt: XAI může snížit sebedůvěru i v případech, kdy ji člověk má oprávněnou. Jinými slovy, léčba overconfidence může způsobit underconfidence. To je relevantní zejména pro expertní domény, kde je zdravá sebedůvěra předpokladem rychlého rozhodování.
Studie neuvádí přesné období sběru dat. Vzhledem k datu přijetí (2024) a publikaci v Information Systems Research (2025) lze odhadovat, že data pocházejí z období kolem 2023 až 2024. Recenzní řízení v information systems typicky trvá 12 až 18 měsíců.
Otevřenou otázkou zůstává, zda efekt přetrvává v čase. Experimenty měřily okamžitý dopad XAI vysvětlení. Zda se metakognitivní přesnost udržuje po týdnech nebo měsících práce s AI, studie neříká.
Zdroje: