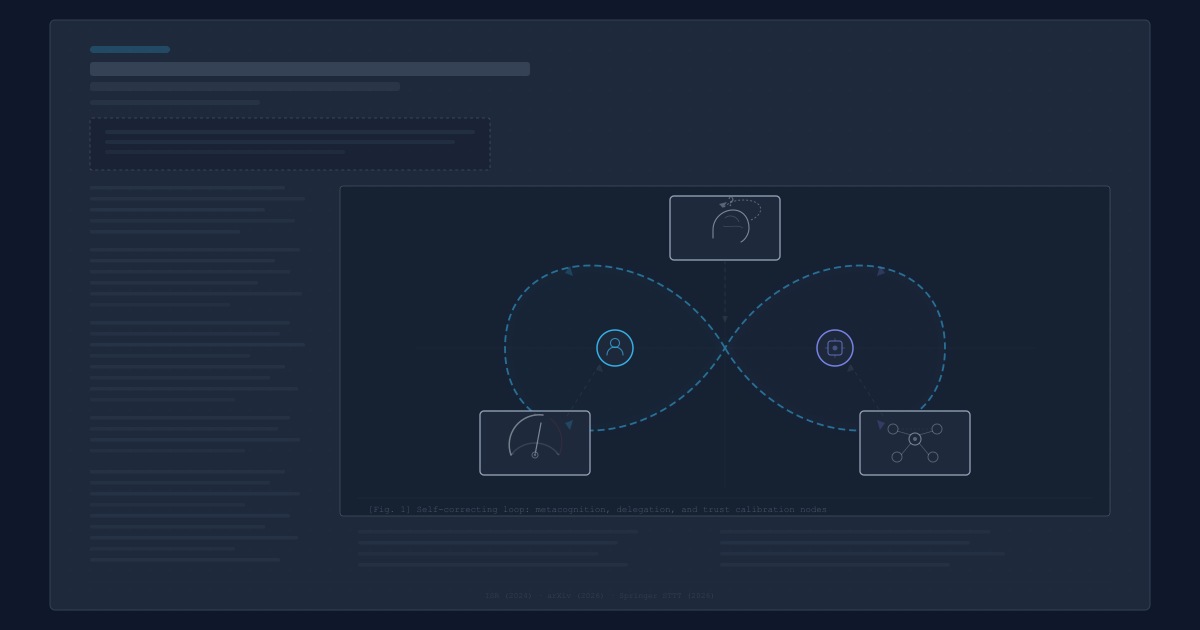
Metakognice, delegace, trust: tři studie mapují, na čem stojí spolupráce člověka s AI
Výzkum z Frankfurtu, DeepMindu a King's College London konverguje ke stejnému závěru: efektivní human-AI loop nestojí na lepší AI, ale na lepší kalibraci. Metakognice, delegace a dynamický trust jako tři pilíře, které se dají designovat.
Foto: FAIN News
Tento článek vznikl agregací informací z veřejně dostupných zdrojů. Nejsme primární zdroj — původní zdroje najdete níže. Mohou vzniknout nepřesnosti.
Tento článek vznikl agregací informací z veřejně dostupných zdrojů. Nejsme primární zdroj — původní zdroje najdete níže. Mohou vzniknout nepřesnosti.
Většina firem dnes řeší otázku „jak AI nasadit." Tři nezávislé výzkumné týmy z Frankfurtu, Londýna a DeepMindu ale ukazují, že mnohem důležitější otázka zní: jak s ní spolupracovat, aniž se rozbije důvěra, rozhodování nebo odpovědnost.
Výzkum posledních měsíců konverguje k překvapivě konzistentnímu závěru. Efektivní spolupráce člověka a AI nestojí na lepších modelech. Stojí na třech pilířích, které se dají naučit, měřit a designovat: metakognici (vím, kdy nevím), delegaci (vím, co komu svěřit) a dynamické kalibraci důvěry (vím, kdy přehodnotit).
Když AI vysvětlí, proč se mýlíte
Tým kolem Moritze von Zahna z Goethe University Frankfurt publikoval v Information Systems Research studii, která převrací zaběhnutý narativ o explainable AI. Běžný argument zní: „AI by měla umět vysvětlit svá rozhodnutí, aby jí lidé víc věřili." von Zahn a kolegové zjistili, že to funguje jinak.
Ve dvou experimentech s profesionály z oblasti nemovitostí a úvěrového hodnocení měřili, jak XAI (explainable AI, neboli vysvětlitelná umělá inteligence) ovlivňuje takzvanou metacognitive accuracy. To je schopnost člověka přesně odhadnout, jak dobře sám zvládá daný úkol. Výsledek: vysvětlení od AI zlepšují metakognitivní přesnost. Ale jen za jedné konkrétní podmínky. AI logika se musí lišit od toho, jak o problému uvažuje člověk.
Jinými slovy: vysvětlení pomáhají nejvíc tehdy, když člověku ukáží, že jeho vlastní úvaha je chybná. Pokud AI dojde ke stejnému závěru stejnou cestou, vysvětlení nepřidá nic. Zajímavá je ale i odvozená implikace, kterou autoři podrobně rozvádějí v preprintu na SSRN. XAI systematicky snižuje overconfidence, tedy přehnanou sebejistotu. Expertům ukazuje slepá místa v jejich vlastním rozhodování. To je zásadní posun oproti představě, že vysvětlitelnost slouží primárně k budování důvěry v AI. Slouží k něčemu cennějšímu: budování realistického sebehodnocení u člověka.
Praktický dopad je přímočarý. Lidé, kteří díky XAI lépe odhadli vlastní limity, začali efektivněji delegovat na AI. Ne proto, že by AI víc věřili. Proto, že lépe věděli, kdy sami nestačí.
🔍 Co je metacognitive accuracy?
Schopnost přesně posoudit vlastní znalosti a výkon. Člověk s vysokou metakognitivní přesností ví, kdy je jeho odpověď spolehlivá a kdy střílí od boku. V kontextu spolupráce s AI to přímo ovlivňuje, jestli se člověk rozhodne úkol řešit sám, nebo ho svěří modelu.
DeepMind navrhuje pravidla pro AI, která zadává práci jiné AI
Nenad Tomašev z Google DeepMind spolu s Matijou Franklinem a Simonem Osinderem publikovali v únoru 2026 na arXiv framework pro inteligentní delegaci v agentic AI sítích. Timing není náhodný. S příchodem agentic workflows, kde AI agenti běží autonomně a zadávají práci dalším agentům, se otázka „kdo komu co svěřil a kdo za to zodpovídá" stala akutní.
Existující přístupy k dekompozici úkolů fungují na jednoduchých heuristikách. Agent dostane úkol, rozloží ho na podúkoly, přidělí je. Tomašev upozorňuje, že tohle selhává ve chvíli, kdy se změní podmínky, selže jeden článek řetězu, nebo vznikne neočekávaný konflikt mezi agenty.
Podle analýzy MarkTechPost framework definuje pět požadavků: dynamické vyhodnocování schopností a zdrojů, adaptivní exekuci reagující na změny, strukturální transparentnost skrze monitoring a audit trail, škálovatelnou koordinaci přes tržní mechanismy a systémovou odolnost proti kaskádovým selháním.
Co je na tom zajímavé z perspektivy human-AI loop: framework explicitně počítá s tím, že delegátor i delegát může být člověk nebo AI. Pravidla pro delegaci jsou symetrická. Člověk delegující na AI agenta by měl dodržovat stejné principy jako AI delegující na jiného AI agenta. Autorita, odpovědnost, specifikace záměru, mechanismy pro budování důvěry.
To je koncepčně důležitý krok. Jak upozorňuje The AI Insider, většina současných frameworků pro human-AI spolupráci staví člověka do role supervizora a AI do role nástroje. Tomašev navrhuje model, kde se role přepínají podle kontextu a kompetencí.
🔍 Proč na tom záleží prakticky?
Firmy začínají nasazovat agentic workflows, kde jeden AI agent orchestruje práci dalších. Kdo nese odpovědnost, když agent subdeleguje úkol na jiného agenta a ten selže? Tomašev nabízí první systematický framework, jak o těchto otázkách přemýšlet.
Důvěra jako dynamický proces, ne nastavení
Třetí dílek skládačky přidává tým kolem Magnuse Liebherra, který v International Journal on Software Tools for Technology Transfer publikoval přehledovou studii o dynamické kalibraci důvěry v AI systémech.
Klíčový argument: důvěra (trust) a důvěryhodnost (trustworthiness) jsou dynamické fenomény, které se vyvíjejí v čase na základě interakční historie. Většina současných přístupů ale pracuje s důvěrou jako s binární proměnnou. Buď AI věříme, nebo ne. Buď je systém důvěryhodný, nebo není.
Liebherr a kolegové rozlišují tři koncepty. Trust je přesvědčení uživatele, že systém bude v dané situaci užitečný a bezpečný. Trustworthiness je objektivní vlastnost systému. A calibrated trust nastává tehdy, když se subjektivní důvěra shoduje s objektivní důvěryhodností. Problém je, že všechny tři se mění. Systém se updatuje, kontext se mění, uživatel získává nové zkušenosti.
Studie mapuje příčiny, které ovlivňují dynamiku důvěry: selhání systému, změny v prostředí, akumulace zkušeností, vliv sociálního kontextu. A navrhuje, že kalibrace důvěry by neměla být jednorázový proces při onboardingu, ale kontinuální mechanismus integrovaný do interakčního designu.
To se potkává s výzkumem von Zahna. Pokud XAI pomáhá kalibrovat metakognici (vím, kdy nevím), pak by obdobný mechanismus měl pomáhat kalibrovat důvěru (vím, kdy důvěřuji příliš, nebo příliš málo). Design implikace: systém by měl aktivně upozorňovat na situace, kde je důvěra uživatele v nesouladu s aktuální výkonností AI.
Tři pilíře jednoho problému
Tyhle tři studie na sebe přirozeně navazují, i když vznikly nezávisle.
von Zahn řeší sebepoznání: vím, kdy jsou moje rozhodnutí spolehlivá? Tomašev řeší mechaniku předávání: když vím, že někdo jiný (člověk nebo AI) to zvládne lépe, jak mu úkol svěřit bezpečně a odpovědně? Liebherr řeší dlouhodobou udržitelnost: jak zajistit, aby kalibrace důvěry fungovala nejen na začátku, ale i po měsících spolupráce, po update modelu, po selhání?
Společně vykreslují obraz toho, co by se dalo nazvat „vědou o human-AI loop." Ne jako buzzword, ale jako skutečný výzkumný program s měřitelnými koncepty a testovatelným designem.
Pro firmy z toho plyne nepříjemná zpráva. Většina současných AI implementací se soustředí na to, co AI umí. Tyto studie ukazují, že to nestačí. Bez designu pro metakognici (von Zahn), delegaci (Tomašev) a dynamický trust (Liebherr) se z AI asistenta stane buď slepě důvěřovaný oracle, nebo ignorovaný nástroj. Obojí je selhání.
A ta příjemná zpráva? Všechny tři problémy jsou řešitelné. Ne dalším tréninkem modelu, ale lepším designem interakce mezi člověkem a strojem.
Zdroje
- Knowing (Not) to Know: Explainable Artificial Intelligence and Human Metacognition
- Knowing (Not) to Know: XAI and human metacognition (SSRN preprint)
- Intelligent AI Delegation
- Google DeepMind Proposes Framework for Intelligent AI Delegation
- DeepMind Study Proposes Rules for How AI Agents Should Delegate
- Dynamic calibration of trust and trustworthiness in AI-enabled systems